Hinet: Novel multi-scenario & multi-task learning with hierarchical information extraction
Meituan 2023 ICDE | 层次化提取信息的多场景和多任务的推荐系统
层次化提取信息的多场景和多任务的推荐系统
多场景(域)和多任务
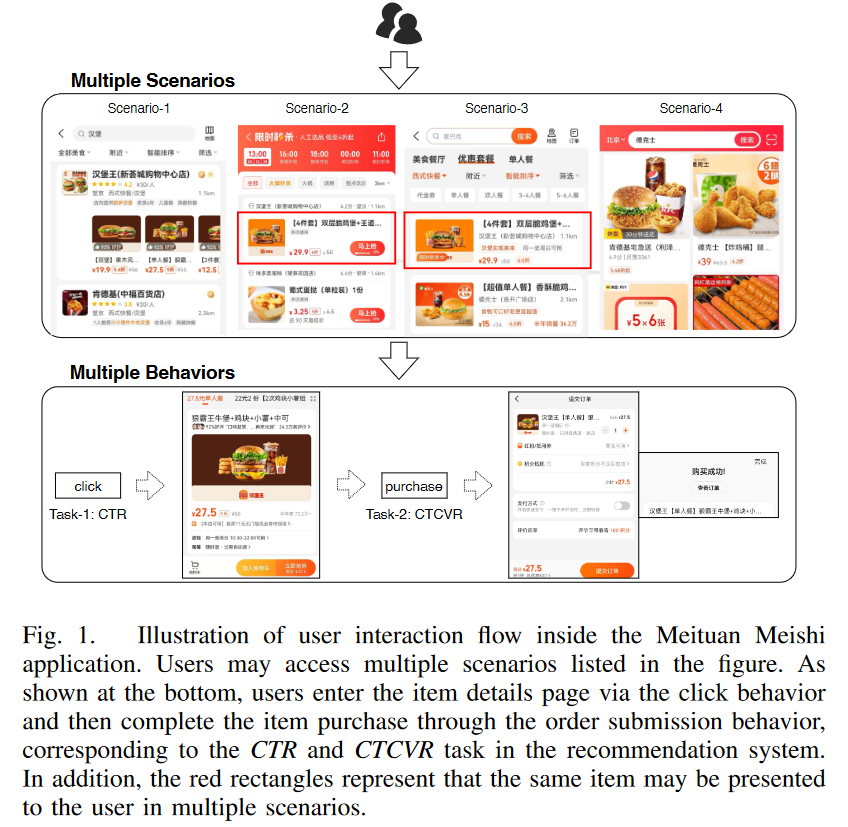
采用美团的多场景和多任务定义,具体的多场景是4种场景,即不同的页面位置。多任务是CTR和CTCVR(点击转化率)。
关于“为什么不能用单个场景单个模型”问题的回答
- 单个场景不能够使用共享的知识
- 某些场景的模型其数据是长尾的
- 多个场景的多个模型带来高计算成本和运维难度
HiNet
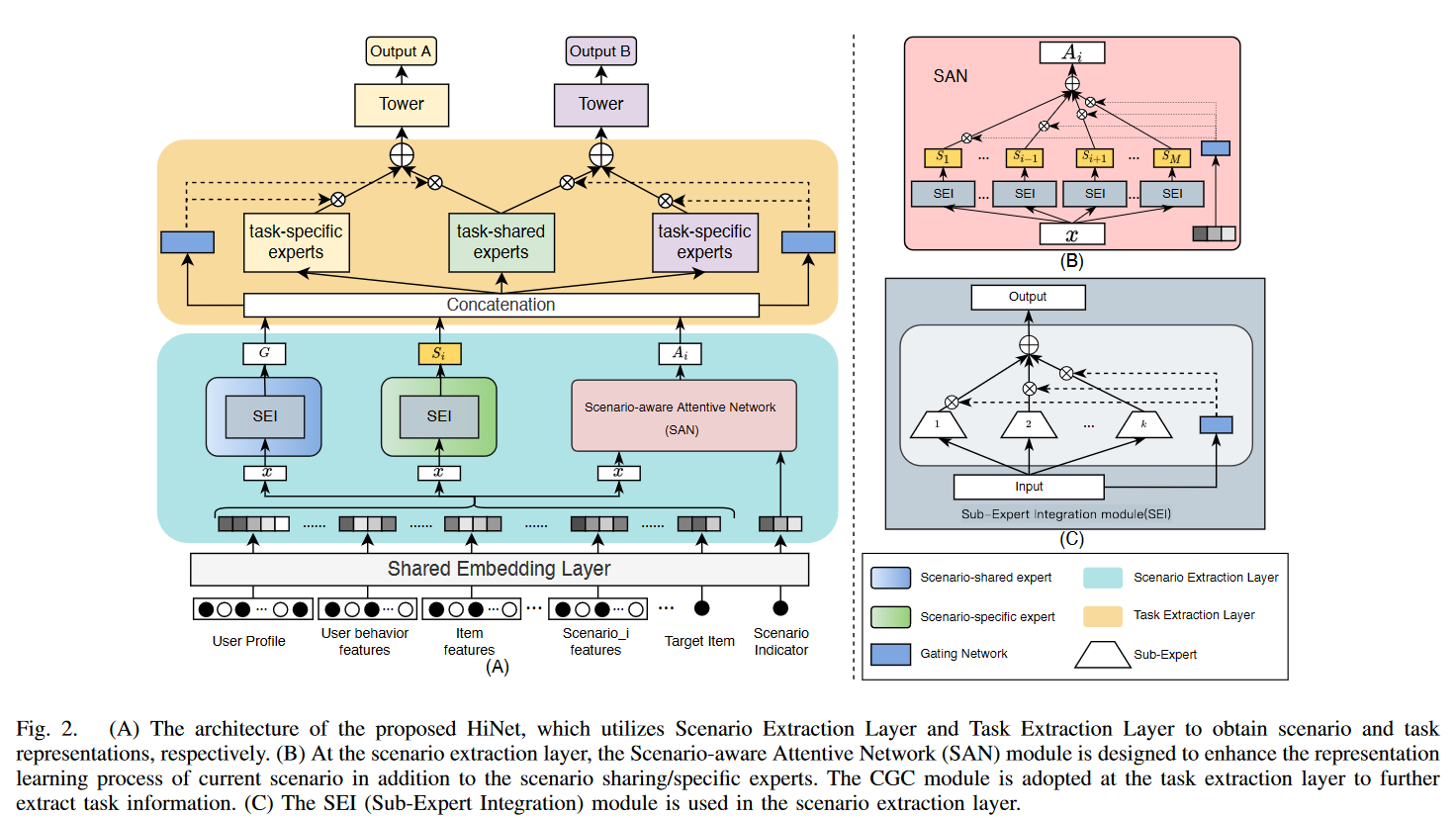
作者提出了分层信息提取网络 Hierarchical information extraction Network (HiNet) 解决多场景域多任务的问题,包括两个部分:
- 场景提取层 Scenario Extraction Layer:又包括场景共享部分和场景特有的部分,还加入了基于场景的注意力网络增强场景的语义表征
- 任务提取层 Task Extraction Layer:分为任务共享部分和任务特有的专家网络,这里的场景特有的专家网络与任务数量一致
Scenario Extraction Layer
主要功能:提取场景通用的和特有的语义,分为场景共享/特有网络和基于场景的注意力网络,只有两个部分,三个网络
场景特有/共享网络
都是专家网络,包含k个子网络,并且有门单元,将门单元的输出与自网络进行点乘,再求和(途中的符号有点像concatenation,但通过公式来看,是求和),可以公式化的表达如下
\[G=\sum_{k=1}^{K_s}g_{sh}^k(x)Q_{sh}^k(x)\\ g_{sh}^k(x)=softmax(W_{sh}^kx)\]其 $ Q_{sh}$ 代表共享的专家网络,$ g$ 为门单元网络,其场景特有的网络也是一样的结构,其输入 $ x$ 都是用户和物品特征的embedding进行concatenation的结果
基于场景的注意力网络
相较于场景提取的网络,这个网络看起来更大一些,$i$ 表示当前的场景编号,因此这里将场景indicator的embedding结果作为门的输入,并且要与不是该场景编号的子专家模型做点乘求和,以此计算当前场景与其它场景的关系。
\[A_i=\sum_{m\neq i}^Mg_a^i(Emb(s_i))S_m\\g_a^i(x)=softmax(W_a^iEmb(s_i))\]由公式可以看出,不同的场景有不同的门单元参数
由于 m不等于i,其实这里的主要作用是利用SAN得到当前场景与其它场景之间的关系
那就没有保留自身的场景信息了?
再场景特有/共享网络中其实会保留场景信息,其输入处理用户与物品的特征,还包括了场景的特征,因此SAN其实就是分析场景之间的关系。
Task Extraction Layer
主要是采用定制化的们控制 Customized Gate Control (CGC),解决多任务中的跷跷板问题(一个任务的表现提高,另一个任务的表现会下降)
CGC在PLE中被提出,解决多任务问题包含两个部分:任务共享的专家模型和任务具体的专家模型(任务的数量等同于专家模型的数量)
task-shared expert networks and taskspecific expert networks. The former is primarily responsible for learning shared information in all tasks of the current scenario, while the latter is used to extract the task-specific information of the current scenario
这句话可以看出,每个场景中任务特定的网络是不同的,即如果在首页,有两个任务(CTR和CTCVR)的专家模型,和在搜索结果页的网络参数不共享,通过公式也可以看出。
\[T_i^j=\delta_i^j(C_i)\left[E_{th}^i(C_i)||E_{tp}^{ij}(C_i)\right]\]公式中的$T_i^j$ 为场景i和任务j的塔的输入,$ \delta_i^j$ 为门,其输入$C_i$ 代表场景提取层concatenation的结果。$E_{th}^i(C_i), E_{tp}^{ij}(C_i)$ 分别是task-shared和task-specific的专家模型结果。
门和塔 ($\tau_i^j$ ) 也是场景和任务特有的:
\[\delta_i^j(C_i)=softmax(W_i^jC_i)\\ \hat{y}_i^j=\tau_i^j(T_i^j)\]Experiment
实验的对比方法可以分为多任务或多场景两种类型,他们都不能直接用于多任务和多场景的评估,作者采取的改良是,多任务的训练了多个模型用于不同的场景,多场景的则训练了多个模型用于不同的任务
使用的是美团的私有数据集,包括6个场景的2个任务
从横向比较的实验结果上看,在全部场景的两个任务中都有提升,泛化性还可以
额外实验
这篇文章确实太多超参数可以调,作者提出了丰富的消融

从结果上看,门单元对于模型的性能是最明显的,其次是层次化,这里的没有层次化,就是不适用场景提取层,只保留任务提取层
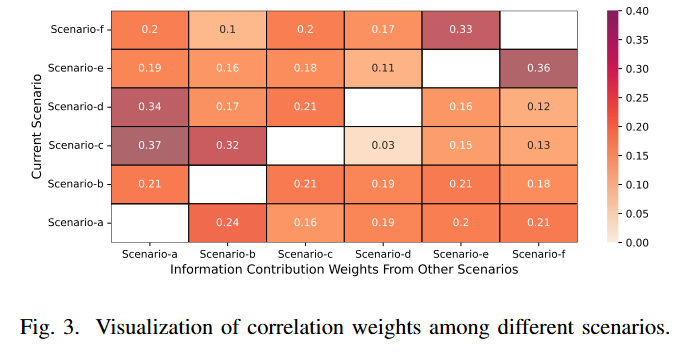
但SAN的提升看起来比较弱,或许他们的场景本身之间就没有什么共享信息,或者说考自身场景的信息就足够了。
但是显然这样的结构对于长尾数据还是很有意义的。数据量比较少的场景e,在没有SAN后的表现下降也是最明显的
接下来作者分析了专家系统的数量,结果表现是随着专家系统的数量增加会涨点,但不是线性的,在实践中应该基本和MMoE一样,设置为经验值/需要调参
SAN的输出结果,表示各场景之间的相关性
个人总结
多任务多场景的模型,实验非常充分,但由于缺少同时处理的模型,其对比是有些不公平的
看起来不足之处在于,随着域的增加,任务的增加,模型的复杂度是线性增加的,每个场景下的每个门、塔都是不一样的。另外论文没有交代模型的细节结构,不知道专家模型里的网络结构是什么样的
为什么SAN的输入用场景的indicator而不继续使用场景的特征呢?目前还没有想到答案