AdaSparse: Learning Adaptively Sparse Structures for Multi-Domain Click-Through Rate Prediction
Alibaba Group 2022 CIKM | 稀疏的结构解决多场景的CTR预测任务
稀疏的结构解决多场景的CTR预测任务
任务:多场景下的CTR
如题,提出可学习的自适应稀疏结构(Learning Adaptively Sparse Structures)的网络用于多领域CTR任务上
背景引入和已有方法
对于多场景(域)下的CTR,用一个统一的模型学习可以改善全局的表现,但在有限数据的泛化性上表现不佳,并且由于计算的复杂度难以用到工业界。
已有的多域解决思路有:
- 把模型切分为特有的部分和共享部分,特定域的参数在特定域的数据机上进行训练
- 根据域去生成模型的参数
其缺点分别是:
- 域与模型的计算成本线性相关,并且存在有某些域训练数据不足的情况,其泛化性不足
- 生成模型参数的方法(引用的是APG)由于需要生成大量参数,可能难以收敛,而且计算复成本也比较高
基于此,作者提出了AdaSparse,要解决上面的两个问题:1、跨域的泛化性 2、低计算成本
Method
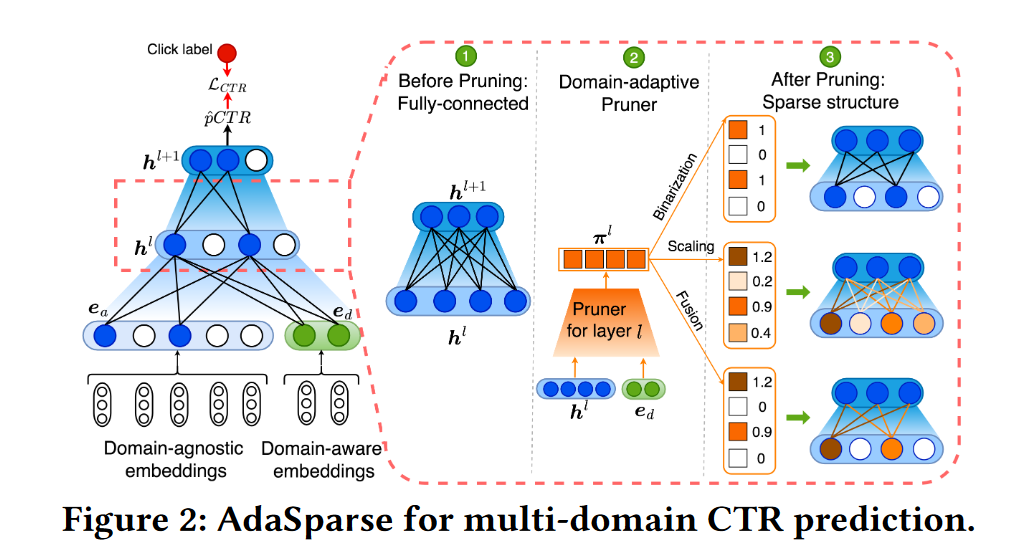
Key idea: 通过域的特征对模型进行剪枝,保留域特定的神经元
1) 将跨域的完整大数据集切分为多个域的子集,并且将数据 $x_i$ 划分为域特定的特征 $x_i^d$ 和域不变的特征 $x_i^a$。对于作者自己的广告业务,根据广告位置的不同,可以分为18个域,每个域的数据集规模差距也很大,模型的优化函数为
\[\min_{\mathbf{W}}\frac{1}{|\mathcal{D}|}\sum_{d}\sum_{i=1}^{|\mathcal{D}^{d}|}\mathcal{L}_{CTR}\left(y_{i},f\left(x_{i}^{d},x_{i}^{a}\right);\{\mathbf{W}^{l}\}_{1\leq l\leq L}\right)\]2) 通过Domain-adaptive Pruner对模型进行剪枝,Pruner是一个轻量级的模型,输入为域特定的特征 $e_d$ ,输出为系数 $\pi^l(d)$,因此,模型第$l$层的输出变为 $h^l(d):=h^l\odot\pi^l(d)$
3种不同的Pruner形式
作者提出了三种不同的剪枝方法,在Figure2上有清晰的表现
Binarization:二值化
主要通过以下公式实现,比较简单,就是用sigmoid将数据映射到0-1,然后小于阈值 $\epsilon$的就变为0。这里需要注意的是,由于刚开始训练时会欠拟合,所以需要逐渐增加 $\alpha$,在实验中,是0.1->5
\[v_{out}=\sigma(\alpha\cdot v_{in}) \\ S_{\epsilon}(v_{out})=sign(|v_{out}|-\epsilon)\]Scaling:放缩
通过Scale将某些重要的表征放大,某些缩小,β用于增强sigmoid的范围,实验中设为2 (类似LHUC)
\[v_{out}=\beta\cdot\sigma(v_{in}),\quad\beta\geq1 \\ S_{\epsilon}(v_{out})=v_{out}\cdot sign(|v_{out}|) .\]Fusion:混合方法
即将二值化和放缩进行融合,小于某个阈值的置为0,大于某个值的还要进行放大。
\[v_{out}=\beta\cdot\sigma(\alpha\cdot v_{in}),\quad\beta\geq1\\S_{\epsilon}(v_{out})=v_{out}\cdot sign(|v_{out}|-\epsilon),\quad\epsilon>0 .\]复杂度分析和正则项控制
复杂度分析: 由于模型本质上只是增加了一小部分矩阵作为Pruner,所以其空间上的复杂度是可以忽略不计的。而计算复杂度只是多进行了剪枝时的点乘(Pruner的网络运算就算没有这个结构,也是要输入到网络中的,所以不是额外的计算量),因此如果考虑 $D$个不同的域 (这里指的是多个完全不同的场景,例如广告位置和使用的View就产生了两个$e_d$的输入),$N_l$为l层的输出维度,额外的计算复杂度为 $O(D * N_l)$
正则:对于稀疏的二值化优化,需要引入正则项,这里定义了稀疏率 $r^l$和期望的稀疏范围,当稀疏率符合要求,就不惩罚;不符合期望,就惩罚,如下公式。
\[R_{s}\left(\{\pi^{l}\}_{1\leq l\leq L}\right)=\frac{1}{L}\sum_{l=1}^{L}\lambda^{l}||r^{l}-r||_{2},\quad r=(r_{min}+r_{max})/2,\] \[\left.\lambda^l=\left\{\begin{array}{cc}0&r^l\in[r_{min},r_{max}]\\\hat{\lambda}\cdot|r^l-r|&r^l\notin[r_{min},r_{max}]\end{array}\right.\right.\]对于 $\hat{\lambda}$,训练时是逐步增加的,以实现随着训练的迭代,惩罚越来越重,实验采用从0.01开始增加,具体的终止值没有说,稀疏率的范围在0.15到0.25
Experiment
在DNN和DCNv2上,对比了一些插件方法,包括 MAML / STAR / APG, 可以SOTA,但提高很有限 实验进行了剪枝方法的比较,发现表现为:融合 > 二值化 > 放缩
泛化性的讨论
1) 人工的选择了三个数据集,两个分布比较类似,一个比较差异化,实验发现作者的网络结构能够较好的捕获不同域的共性。 2) 将不同域的数据通过大小分为多个桶,实验发现AdaSparse在长尾数据的桶上表现良好,说明在数据集比较小的域上也有很好的泛化性。
域数量的讨论:当域的数量较多时,表现会得到提示,但不是随着域的数量增加而持续增加的,表现有可能会降低
稀疏率范围的讨论:在0.15-2.0时表现最佳,增长和下降都会降低,当大于0.35时劣于baseline
个人总结
提出了一个非常简单、有效、轻量级的方法实现多域的CTR,实验结果显示提升优先,但是是基于他们的复杂度而言的。已经在复杂度和效果上达到了一个很好的trade-off.