APG: Adaptive Parameter Generation Network for Click-Through Rate Prediction
Alibaba Group 2022 NIPS | 生成式的网络权重解决多场景的CTR预测任务
生成式的网络权重解决多场景的CTR预测任务
解决多域下的CTR任务
不同的是,这里没有直接使用Multi-domain这个词,而是强调不同的特征(论文中以用户的类型Cold User/ Active User举例)会有不同的分布
背景引入
已有的CTR工作可以分为两类:
- Focus on x,意在丰富特征空间
- Focus on F,意在提高模型的结构
但实际上,这两类并没有考虑数据分布的差异问题,例如不同的用户、类型(其实就是后续研究的Multi-domain的概念)。因为统一参数的模型无法捕捉不同分布之间的特征,而且不同分布下有长尾问题。
Method
基于此作者提出了使用一个模型去生成模型参数的paradigm
同时带来了两个问题:
时间与空间增长: 对于模型的权重矩阵为$N*M$ 维,如果用一个简单的MLP去生成矩阵,设输入的维度为D,其空间和时间的计算成本扩大了D倍($O(NM) -> O(NMD)$)
效果不好(sub-effective):因为没有考虑到各个分布之间的共性,而且这样其实也有长尾数据问题
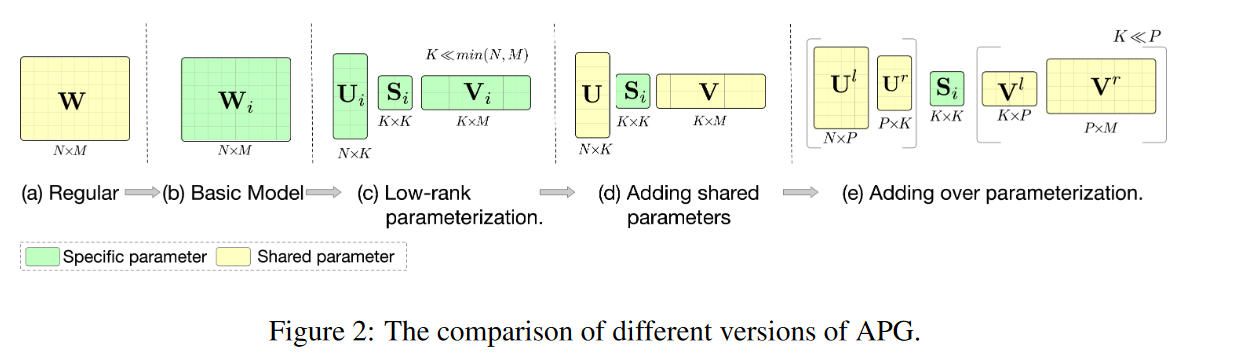
作者提出了解决上面两个问题的方案,如图2所示:
参考低秩分解,将权重从 $NM$ 分解为 $US*V$,而中间转换维度为K,远小于N*M
将U和V作为共享权重,对于每一个输入实例,只生成S,而且在USV的基础上提出over parameter,丰富共享参数的维度
Condition Design
非常重要的部分,介绍了他们对APG生成模型的输入,其实就是multi-domain的domain特征,这里用词为condition,作者介绍了三种方案
Group-wise: 将用户切分为多个组,同一个组的用户应该有相似度模式,例如将用户分为cold和active
Mix-wise:使用更加丰富的特征,例如可以同时使用用户的类型、用户的所在地等等。在附录的举例中,提到了可以使用用户topK个item的embedding。这里输入APG有两种方式:
- Input Aggregation:只有一个APG,在输入前对多个条件的embedding进行融合,例如topk物品平均与用户类型的embedding进行融合,再输入到APG,融合方法可以有concatenation,Mean或者Attention
- Output Aggregation: 有多个APG,不同的特征输入不同的APG,将多个AGP的输出进行融合
Self-wise: 不再需要先验知识,而是用模型表征作为APG的输入,以为模型的表征本身就是对输入特征的抽象了,这里举例是用模型 l-1层的表征作为AGP的输出产生 l 层的模型参数
方法细节
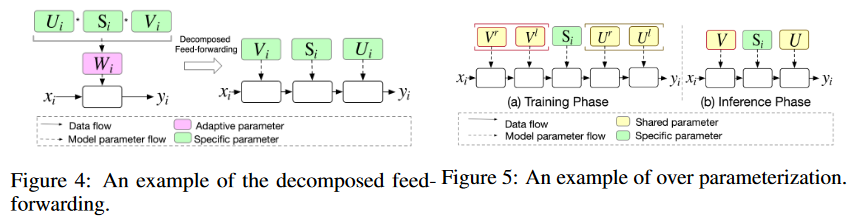
作者另外提出了解耦前向(Decomposed Feed-forward)的思路进一步降低计算的复杂度,避免了将USV再融合为W的过程。
此外还将解耦前向与过参数(Over parameters)结合,这里给出了三篇引用解释了为什么要使用过参数方法:1、因为P远大于K,所以增强了模型的大小(通常而言,模型越大能力越强)2、多个矩阵乘机包含隐式的正则化,可以提高模型泛化性。
图四与图五可以很好的表示上述的两个改进。
Experiment
采用了多种数据集,包括Amazon,MovieLen,IAAC和IndusData,比较了多种方法,以CTR方法和多任务方法(MMoE和[Star](/posts/STAR))。从横向的比较伤,涨点是很显著的。
在消融实验上,作者将不同的APG setting分为V1-V5,分别表示为
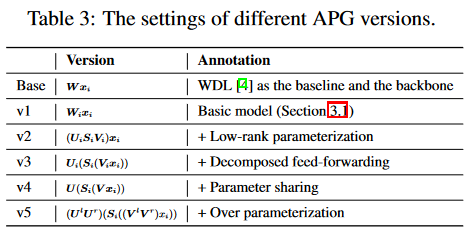
从实验结果来看,低秩分解矩阵与原矩阵有几乎一致的效果,但降低了时间空间的复杂度;参数共享增加了模型表现,说明存在不同分布之间的共性,并加以利用;增加了过参数化后,模型泛化性进一步提高,完整的效果是最好的。