One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction
Alibaba Group 2021 CIKM | 共享和场景特定的星形网络解决多场景的CTR预测任务
共享和场景特定的星形网络解决多场景的CTR预测任务
多域下的CTR预测任务
提出了用星形拓扑学的模型结构,存在一个共享的模型作为星形的中心,周围是各个域的模型,已经是Multi-Domain的经典方法。
问题引入与方法介绍
作者以阿里淘宝的业务作为多域的介绍,例如淘宝的Banner和猜你喜欢两个推荐位置,就属于两个域
统一的模型没有办法在不同的域之间有很好的泛化性,而多个模型又有的缺点:1是某些域的数据集不足 2是带来了更多的资源消耗和人力成本(这里的人力成本我理解为在后端开发中,需要调用对应的模型,还需要额外的运维)
为什么无法用多任务的思路解决多域问题?
Due to the heterogeneity of tasks, existing multi-task learning approaches focus on sharing information in the bottom layers but keeping separate task-specific output layers. Directly adapting multi-task approaches to multi-domain CTR prediction can not sufficiently exploit the domain relationship in the label space and neglect the distinct data distribution of different domains.
我理解为:多个任务重点在低维上共享信息,输出侧进行任务的区分,不同的任务在同一个域下,他们只是目标不同,其输入没有差异。如果直接使用多任务的思路,就没有利用维度之间的关系,也没办法区分。以MMoE为例,如果直接的将输出变为不同域的CTR,模型并没有将各个域进行很好的区分。看似合理的改进应该是将gate的输入改为域的特征?
Method
提出STAR模型,由三个部分构成:域分离的归一化、星形拓扑结构、辅助模型
域分离的归一化 Partitioned Normalization (PN)
原因:在神经网络中,归一化基于数据集的方差和均值是一致的,因此只需要记录整体数据集的方差和均值,就可以在推理时实现归一化,而在训练时用Batch的均值和方差归一化。
\[Training: \mathbf{z'}=\gamma\frac{\mathbf{z}-E}{\sqrt{Var+\epsilon}}+\beta\\\] \[Testing: \mathbf{z}^{\prime}=\gamma\frac{\mathbf{z}-E}{\sqrt{Var+\epsilon}}+\beta\]但在不同的域中,每个域的均值和方差很不一样,因此作者提出了基于域的归一化方法:
\[Training: z'=(\gamma*\gamma_{p})\frac{z-\mu}{\sqrt{\sigma^{2}+\epsilon}}+(\beta+\beta_{p})\] \[Testing: \mathrm{z'}=(\gamma*\gamma_{p})\frac{\mathrm{z}-E_{p}}{\sqrt{Var_{p}+\epsilon}}+(\beta+\beta_{p})\]引入 $ \gamma_p $ 和 $ \beta_p$ 代表第p个域的均值和方差,指的注意的是这里的两个值代表放缩和偏移,并不是将原来的均值和方差进行替换,推理时的均值也为整个域得到的均值
星形拓扑结构的全连接网络 Star Topology FCN
如图5,就是共享模型在中间,周围是特定域的全连接网络。共享网络在所有数据上更新,特定域网络在特定域的数据集中才更新。
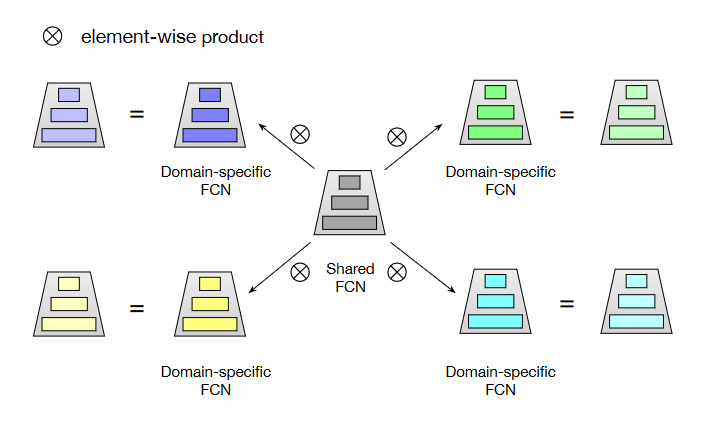
网络不是将模型的输出进行点乘,而是将模型的参数进行点乘
\[W_p^\star=W_p\otimes W,b_p^\star=b_p+b\\ out_p=\phi((W_p^\star)^\top in_p+b_p^\star),\]其中 $ W_p, W_p^\star,W$ 分别是特定域模型的参数、最终模型的参数和共享模型的参数,偏移量与之类似,$ \phi$ 为激活函数。
辅助模型 Auxiliary Network
作者认为多域的CTR模型中,应该有两个特点:1是能够提取域特征 2是使该特征能够有效的影响结果
因此辅助模型的作用就是进行区分,并加以影响。辅助模型是一个简单的两层全连接网络,其输出会和星形模型的输出进行相加$\mathrm{Sigmoid}(s_{m}+s_{a}).$ ,得到最终的结果
Experiment
因为Star是多域中比较早期的任务,当时还没有什么多域的模型,所以baseline包括:
- Base:简单的7层全连接网络,训练时混合了不同域的所有样本
- Multi-Task Model:包括Shared Bottom和MMoE
- Multi-Domain Model: MulANN和Cross-Stitch
实验结果可以看出,Multi-Domain的模型明显优于Base和多任务模型,Star比其他两个任务提高了约0.01的auc
| 消融实验做了四种: Base (BN) | Base (PN) | STAR FCN (BN) | STAR FCN (PN) |
论证了PN和Star结构的效果
此外还将辅助模型作为插件用于所有方法上,实验证明辅助模型对于所有模型都有涨点
个人总结:
星形结构更像是一种让人impressive的概念,其实整体的思路和MMoE有异曲同工之妙。
提出的PN是非常直觉性的,应该可以推广到所有的多域学习中解决数据不平衡问题。
不足之处在于,这里的domain似乎是固定数量的,在新的domain出现时,泛化性不知道怎么样。
另外,为什么采用矩阵直接进行点乘,而不是用输出的点乘?还是我的理解出现了问题?等待实验时看源代码再解决这个问题。