Scenario-Adaptive Feature Interaction for Click-Through Rate Prediction
Tencent 2023 KDD | 基于transformer的网络结构实现多场景下的CTR预测,强表征能力、低参数和高解释性
基于transformer的网络结构实现多场景下的CTR预测,强表征能力、低参数和高解释性
问题的引入
已有的多场景模型存在有三个缺点:
- 不能够对场景之间的差异性建模 (Insufficient Distinction Modeling)
- 场景增加、模型参数也增加、效率低(Inefficiency with the increase of scenarios)
- 缺乏解释性(lack of interpretability)
基于此,作者提出了基于Scenario-Adaptive Transformer(SATrans)模型解决了上述三个问题,SATrans 能够清楚的对特征进行交互,来区分不同的场景
as far as we know, none of existing MultiScenario Modeling approaches takes explicit feature interaction into consideration when modeling scenario distinctions
在论文中反复用到Explicit这个词,可以解释为清楚的,因为他们的方法用注意力机制本身解释性就比较强,另一方面也可以翻译为直接了当的,explicit feature interaction就是在特征之间进行之间的内积等操作,在Relative work中,作者提到DCN也是对high-order(理解为高纬度)特征进行直接交互,这样的特征交互方式,和使用Gate是不一样的
Insight
不同的场景中,不同特征的交互模型应该有区别,作者以广告推荐系统为例,考虑性别、地点和品牌各种特征。
在食物推荐场景,品牌和地点的特征对可能会更有意义
在服装推荐场景,性别和品牌的特征对可能会更有意义
而在已有的方法中,没有清楚地捕捉到考虑到类似的、不同特征之间的交互
基于此作者提出了SATrans:
- Transformer 结构对特征进行高纬度的特征交互,多头注意力机制判断特征的意义
- Scenario Encoder 做不同场景之间的变换
- Scenario-Adaptive Interacting Layer 衡量不同特征对之间的关联性
Method
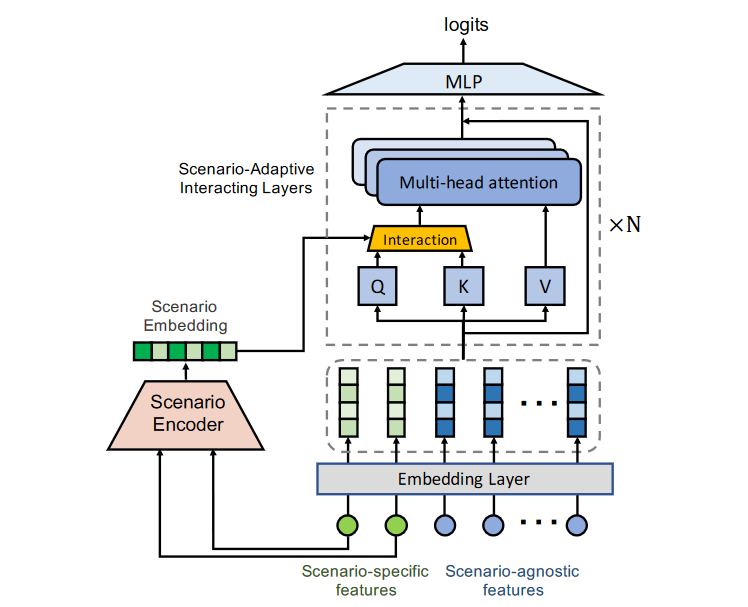
整体的模型如Figure 1,Figure 1很好的可视化了模型的整体架构以及输入输出,输出就是点击率的logits,输入包括场景特定特征与场景无关的特征。包括Scenario Encoder和Scenario-Adaptive Interacting(SAI) Layers两个部分
- 值得特别注意的是Scenario Encoder的部分,其输入为场景特定的特征,而且是原始特征,没有经过Shared Embedding,和现有很多模型不一样
- 第二个值得关注的地方在于,在Scenario-Adaptive Interacting Layers中有interaction模块,和原始的Transformer输入既当QK又当V不同
Scenario Encoder
作者考虑了3中结构作为Scenario Encoder,清楚了当
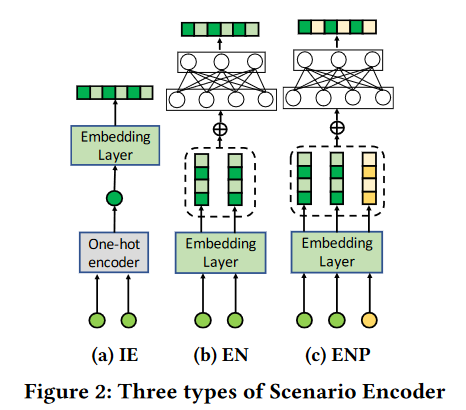
(a) Independent Embedding(IE):最简单的方式,当输入的场景特征不同时,能够产生不同的Scenario Embedding
(b) Encoder Network(EN):先使用Embedding层再经过MLP,使用MLP使得不同的场景之间也可以有shared knowledge
用输入$ x^s, x^a $ 分别代表特征特定和无关的特征,输入表示为
\[\mathbf{x}=[\mathbf{x}^s;\mathbf{x}^a]=[\mathbf{x}_1^s;\ldots;\mathbf{x}_M^s;\mathbf{x}_1^a;\ldots;\mathbf{x}_{N-M}^a],\]EN可以表示为:
\[\mathbf{s}=\mathbf{W}_{\mathbf{s}}\mathrm{ReLU}(\mathbf{e}^{s}).\]$ e,W $ 分别代表embedding之后的结果,以及MLP的权重,可见这里的MLP没有Bias
(c) Encoding Network with Structural Position IDs(ENP): 由于场景特征会在不同的Transformer层中进行,ENP考虑加入了不同层的信息,图中黄色的就是层的id,整个ENP用公式表示为:
\[\mathrm{s}_{l,h}=\mathrm{W}_s\mathrm{ReLU}(\mathrm{Concat}(\mathrm{e}^s,\mathrm{p}_{l,h})),\]$ p_{l,h}$ 代表第 $ l $ 层,$ h $ 头的结果,在后面的SAI中,会将这个输入分为 $ s_Q, s_K $ ,即不同的Q和K其实他的id也是不一样的,但对于IE和EN两种策略,不区分Q和K
Scenario-Adaptive Interacting(SAI) Layers
对于多层的Transformer模型,定义第$ i $ 层的输入为$ h_i $ ,那么对于第一层,其实 $ h_1 = e_1 $ ,其注意力机制,作者表示为
\[\alpha_{i,j}^{(h)}=\frac{\exp(\phi^{(h)}(\mathbf{h}_{i},\mathbf{h}_{j}))}{\sum_{k}^{N}\exp(\phi^{(h)}(\mathbf{h}_{i},\mathbf{h}_{k})}\\\phi^{(h)}(\mathbf{h}_{i},\mathbf{h}_{j})=\langle\mathbf{W}_{\mathrm{Q}}^{(h)}\mathbf{h}_{i},\mathbf{W}_{\mathrm{K}}^{(h)}\mathbf{h}_{j}\rangle\]其实就是Transformer的多头注意力机制,原始的输入需要先经过一个MLP,由此建立多种映射关系,经过了映射的可以理解为Q和K,再通过内积进行注意力计算,最终得到的 $ \alpha $ 代表权重,那么这一层的输出就是
\[\hat{\mathbf{h}}_i^{(h)}=\sum_l^M\alpha_{i,j}^{(h)}(\mathbf{W}_\mathrm{V}^{(h)}\mathbf{h}_l),\]以上是标准的Transformer结构中的注意力机制,在本文中,输入和输出要考虑场景Encoder的输出,所以作者把问题归纳为一下公式,即设计一个输入为 $\mathrm{h}i,\mathrm{h}_j,\mathrm{s}\mathrm{Q}^{(h)},\mathrm{s}_\mathrm{K}^{(h)}$ 的注意力机制
\[\phi_{sa}^{(h)}(\mathrm{h}_i,\mathrm{h}_j,\mathrm{s}_\mathrm{Q}^{(h)},\mathrm{s}_\mathrm{K}^{(h)}).\]其中 $ s $ 很好理解,就是场景Encoder的输出,$\mathrm{h}_i,\mathrm{h}_j$ 代表第 $h$ 个头在特征 $ i, j $ 的输入(上一个头的输出)
基于作者将SAI也设计了三种不同的结构,如Figure 3所示,直接理解下图的三个forward的逻辑,可以抛弃上面和下面的公式
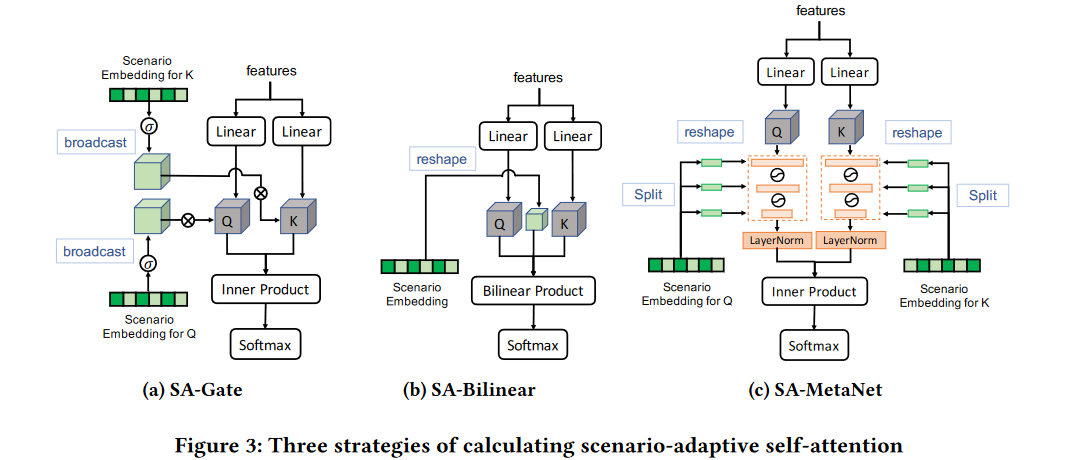
(a) SA-Gate:这个gate表达的很好,其实就是类似于gate的作用,将场景Encoder的输出作为权重,与K相乘,使用sigmoid激活,用公式表达为
\[\phi_{s\boldsymbol{a}}^{(\boldsymbol{h})}(\mathbf{h}_{\boldsymbol{i}},\mathbf{h}_{\boldsymbol{j}},\mathbf{s}_{\mathrm{O}}^{(\boldsymbol{h})},\mathbf{s}_{\mathrm{K}}^{(\boldsymbol{h})})=\langle\sigma(\mathbf{s}_{\mathrm{O}}^{(\boldsymbol{h})})\circ(\mathbf{W}_{\mathrm{O}}^{(\boldsymbol{h})}\mathbf{h}_{\boldsymbol{i}}),\sigma(\mathbf{s}_{\mathrm{K}}^{(\boldsymbol{h})})\circ(\mathbf{W}_{\mathrm{K}}^{(\boldsymbol{h})}\mathbf{h}_{j})\rangle\]虽然这里有K和Q的Embedding,但如果Scenario Encoder是IE和EN,这两个是一样的
(b) SA-Bilinear: 相较于Gate,这里的Bilinear Product是矩阵相乘,需要将一维的Scenario Embedding先进行reshape,公式表达为
\[\phi_{sa}^{(h)}(\mathbf{h}_{i},\mathbf{h}_{j},\mathbf{s}_{\mathrm{Q}}^{(h)},\mathbf{s}_{\mathrm{K}}^{(h)})=(\mathbf{W}_{\mathrm{Q}}^{(h)}\mathbf{h}_{j})^{\top}\mathbf{S}(\mathbf{W}_{\mathrm{K}}^{(h)}\mathbf{h}_{i}),\\\mathrm{where~S}=\mathrm{Reshape}(\mathbf{s}_{\mathrm{Q}}^{(h)})\in\mathbb{R}^{d\times d}.\]这里原本 $ s_{\mathrm{Q}}^{(h)}\in\mathbb{R}^{L/H} $ ,H是多头注意力的头数量
(c) SA-MeTaNet: 最复杂的方式,使用MetaNet机制,先将输入的Scenario Embedding分成$ P $ 个片段,公式表示为$ [s_{Q,1}^{(h)};\ldots;s_{Q,P}^{(h)}] $ ,MetaNet表示为
\[f_{s_{\mathrm{Q}}^{(h)}}^{\mathrm{m}}=\mathbf{W}_{1}\delta(\mathbf{W}_{2}\delta(\ldots\delta(\mathbf{W}_{P}\mathbf{x})\ldots))\\\mathrm{where~W}_{p}=\mathrm{Reshape}(s_{\mathrm{Q},p}^{(h)}),\mathrm{W}_{p}\in\mathbb{R}^{d_{p-1}\times d_{p}},\]这里是对于输入x而言的,在作者的网络中,输入其实是经过MLP的Q和K,所以最终的公式为
\[\phi_{sa}^{(h)}(\mathbf{h}_{i},\mathbf{h}_{j},s_{\mathrm{Q}}^{(h)},s_{\mathrm{K}}^{(h)})=\langle\mathrm{LN}_{\mathrm{Q}}^{(h)}(f_{s_{\mathrm{Q}}^{(h)}}^{\mathrm{m}}(\mathbf{W}_{\mathrm{Q}}^{(h)}\mathbf{h}_{i}),\mathrm{LN}_{\mathrm{K}}^{(h)}(f_{s_{\mathrm{K}}^{(h)}}^{\mathrm{m}}(\mathbf{W}_{\mathrm{K}}^{(h)}\mathbf{h}_{j}))\rangle,\]这个公式可以改进为以下公式,以实现在多头上的并行运算,这一点和Transformer原本的多头注意力也是一样
\[\phi_{s\boldsymbol{a}}^{(\boldsymbol{h})}(\mathbf{h}_{\boldsymbol{i}},\mathbf{h}_{\boldsymbol{j}},\mathbf{s}_{\mathbf{Q}},\mathbf{s}_{\mathbf{K}})=\langle[\mathrm{LN}_{\mathbf{Q}}(f_{\mathbf{s}_{\mathbf{Q}}}^{\mathbf{m}}(\mathbf{W}_{\mathbf{Q}}\mathbf{h}_{\boldsymbol{i}})]^{\boldsymbol{h}},[\mathrm{LN}_{\mathbf{K}}(f_{\mathbf{s}_{\mathbf{K}}}^{\mathbf{m}}(\mathbf{W}_{\mathbf{K}}\mathbf{h}_{\boldsymbol{j}})]^{\boldsymbol{h}})\rangle,\]除了使用MetaNet,作者还使用了Transformer中用到的LayerNorm,因为这里想要进行特征交叉,计算的是特征之间的方差和均值进行归一化,表示第i个特征在整个特征上的“轻重”要被归一化
最后的MLP
注意最后又经过了一个MLP的结构做回归,注意这里是有bias的
\[p_{\mathrm{CTR}}=\sigma(\mathrm{W_{O}h^{Out}+b_{O}}),\]实验与结果
数据集选择了Ali-CCP和Ali-Mama数据集,以及WeChat-MS数据集。
对比方法分为两种类型:
- Single-scenario Feature Interaction (FI) approaches: DCN,DeepFM等
- Multi-Task Learning models:MMoE,Shared Bottom,PLE,AdaSparse
在模型的表征能力上,在三个数据集基本都SOTA,而且p值表现也比较好,提升明显
在模型的参数量上,用一张Figure 5表示随场景增加模型的参数量变化
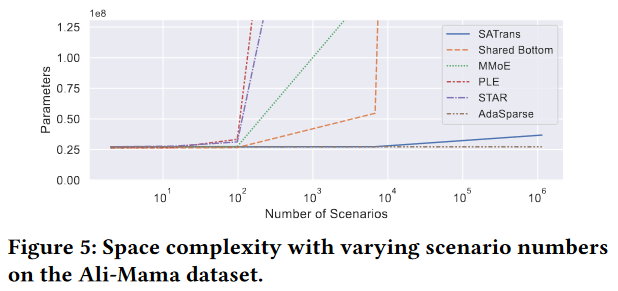
不难理解,因为MMoE没增加一个场景就要有新的专家层,PLE还需要增加门结构,STAR每增加一个场景,要有新的星形分支网络,AdaSparse不变,因为场景增加只是改变pruner的场景特征输入。
在模型的解释性上,作者从实力级别的解释下和场景级别的解释性上做了可视化
Figure 6展示实例级别,可以看到商品的价格、消费等级和购物的深度程度(<price=CNY_32800, consumption_grade4=high, shopping_depth5=deep>)就是高相关的,支撑这个实例预测为点击label为1的结果
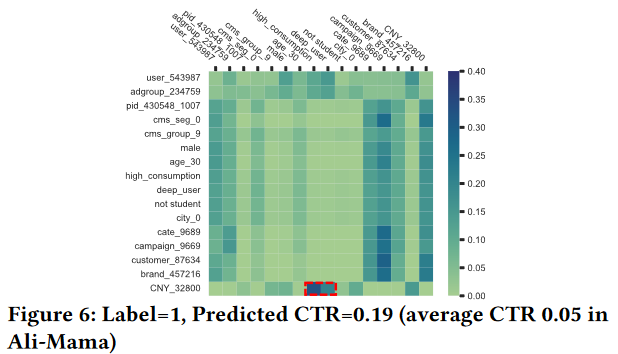
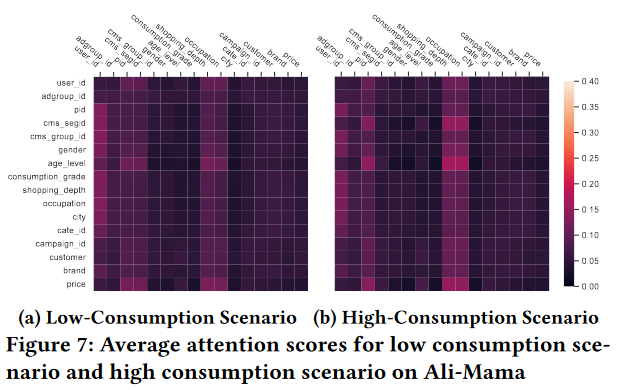
Figure 7展示场景级别,可以看到低消费场景和高消费场景集中于不同的特征组合,例如<age_level, shopping_depth>, <age_level, occupation> or <cms_segid, occupation>
个人总结
很好利用Transformer在精排任务中,实验结果也充分体现了作者所称的三个优势,即模型的表达能力、效率以及解释性。
数据集不仅采用了ali的数据,还有其他家公司的,也很充分和solid
相比SAI模块,其实Scenario Encoder模块更有意思,用Layer Id和场景特征作为输入,大大降低了模型的参数量,似乎所有的Gate结构都可以替换?例如Pepnet中就不需要那么多Gate模型,只需要一个包含Gate Id作为输入的Gate网络就可以?