Reconstructive Neuron Pruning for Backdoor Defense
Xidian 2023 ICML
概要
提出了一种后门模型的防御方法RNP,具体而言是模型净化。只需要一小部分干净数据集(实验中为1%),使后门模型暴露受损神经元,并对其做剪枝。
整体思路:是通过不对称的Unlearning实现的,即用一小部分干净样本做Unlearning暴露干净样本无关的神经元,再用同样数据集做Learning凸显干净数据的神经元,以此为依据推断出后门神经元,再做剪枝。
开源代码: https://github.com/bboylyg/RNP
Unlearning and recovering process
Unlearning via a neuron-level 遗忘学习/不学习,对已有的模型,优化函数为原目标函数的相反数,从而使模型遗忘所学习到特征。
这个过程优化的参数是neuron-level的。在开源代码中可以看出,neuron-level指的是优化模型的所有神经元,即所有参数。
Recovering via filter-level recover unlearned model增强了对干净数据特征的提取能力。 这个过程是filter-level的,代码显示为只优化BatchNorm Layer.
Prune 在代码中,显示了两种Prune的策略,1是根据阈值进行mask,2是选择mask得分最低的作为mask mask的得分:在Recovering的过程中,并不是学习一个全新的BatchNorm的参数,而是如公式3,学习一个Mask。那么mask越大(最大为1)说明这个神经元保留的更多,越小说明保留得越少。因此mask越小的,说明其对于干净数据集的决定性约弱,可以被修剪。 
为什么要使用不对称的学习方式(在同一数据上进行Unlearn和Learn,但是优化的模型参数不同)?
如果直接按照神经元级别或者滤波器级别进行遗忘和学习,就相当于把模型的神经元给翻转再恢复,这样还是会形成后门。所以用一种不对等的学习形式。
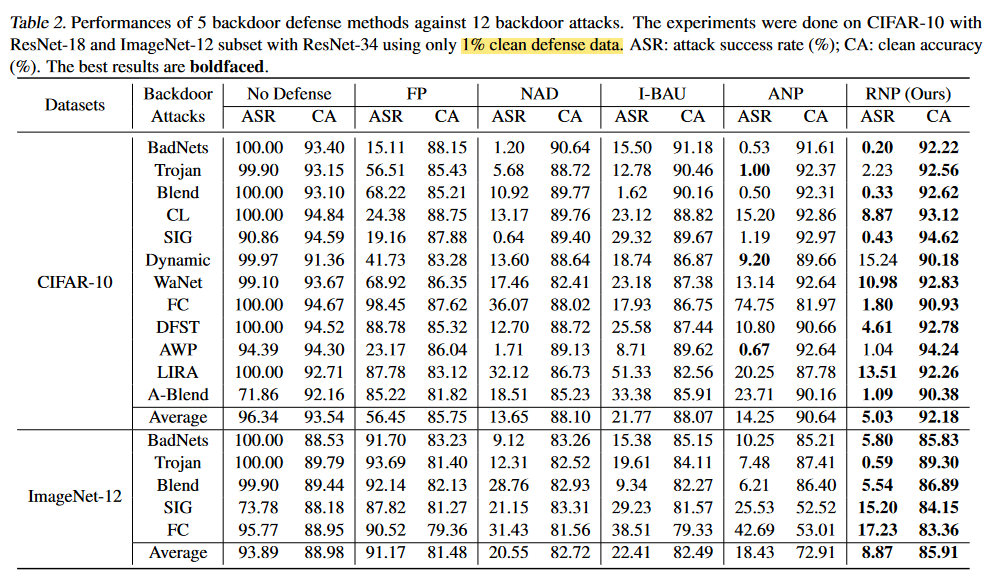
Experiment
实验结果非常震撼,对12种攻击都有效,而且几乎SOTA