Revisiting the Assumption of Latent Separability for Backdoor Defenses
Tsinghua 2023 ICLR
挑战:有毒样本与干净样本容易产生表征差异的问题
很多的方法其实都证明了有毒样本与干净样本在模型的表征(Latent)层面有区别,并由此提出了一系列的防御方法,如
- Detecting backdoor attacks on deep neural networks by activation clustering
- Defending Against Backdoor Attacks by Layer-wise Feature Analysis
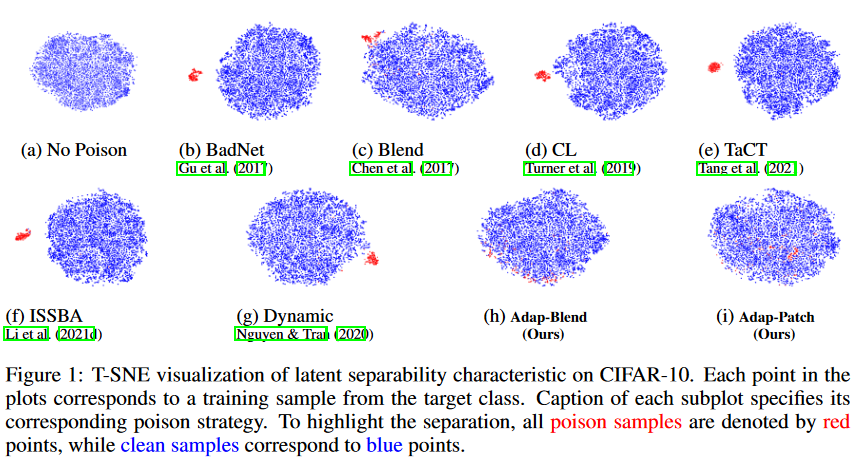
论文首先用T-SNE降维的可视化分析了不同攻击的表征分离情况,如图所示,他们提出的Adap-Patch和Adap-Blend攻击方法表征空间上,使有毒样本与干净样本更加紧密。
Motivation
结合两篇文献,分析了后门的本质:
- 有毒图像存在主导特征(dominantly strong signal),主导特征压制了其它特征
- 模型对有毒图像产生一条捷径
因此,他们提出的攻击方法需要:
- 要压制有毒图像中的主导特征
- 要产生多条判断路径
Method
- Regularization Samples 加入触发器的样本不再全部指定为目标的标签,而是有一部分保持原有标签,打破主导特征
- 对于加了触发器不改变标签的样本,称为payload sample
- 对于加了触发器改变标签的样本,称为regularization sample
- conservation ratio in [0,1) 控制payload : regularization的比例
- Asymmetric Triggers 在测试阶段采用具有主导特征的样本,保证了攻击成功
- Trigger Diversification 使用多个触发器产生有毒样本,打破捷径,建立多条判断路径
INSTANTIATIONS
采用经典的BadNet和Patch作为Method的实例
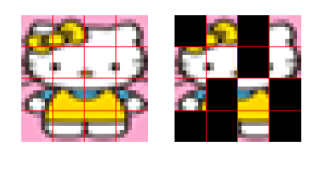
- 对于BadNet,建立多种触发器,如图6的(c)~(g)和(j)~(n)
- 对于Blend(Patch),将trigger氛围16个片段,选择50%进行嵌入,如图6(b)(i),但在测试阶段还是会使用完整的trigger,如图6(a)(h)

Result
- 在攻击上,仍然保持了还不错的攻击成功率
- 在防御上,使用经典的表征分离防御,明显优于其他方法
个人结合复现实验的观点:对于超参数有明显要求,当毒化率高时,表征仍然可分;当毒化率低时,攻击不成功。且,这个Method的泛化性也较弱。
本文由作者按照 CC BY 4.0 进行授权